Node.js Child Processes, 你需要知道的一切
就单进程而言,Node.js 的单线程非阻塞执行表现良好。然而,单 CPU 单进程的方式不足以处理应用程序日益增长的工作负载。
无论你的服务器有多强大,需要承认的是,单线程只能承受有限的负荷。
Node 单线程执行 js 的事实并不意味着我们不能利用多进程、多处理器的优势。
使用多进程是扩展 Node 应用最好的方式。Node.js 本就是设计成利用多节点(nodes)构建分布式应用的。这也是为什么它叫 Node。可扩展性是 Node 这个平台的基因,并且是你在应用程序生命周期开始就应该考虑的事情。
请注意,在继续阅读这篇文章之前,你需要对 Node.js 的 events 和 streams 有非常好的理解。如果你还不熟悉这些,我建议你先阅读另外两篇文章:
Child Processes 模块
我们可以非常容易地使用 Node 的child_process模块新开一个子进程,并且这些子进程可以非常容易地通过消息系统进行通信。
通过在子进程中运行系统命令,child_process模块可以使我们能够获取操作系统提供的许多能力。
比如,我们可以控制子进程的输入流,监听它的输出流。我们还能控制传递给底层操作系统命令的的参数,并且我们可以对命令的输出做任何想做的事。举个例子,我们可以把一个命令的输出作为另一个命令的输入(pipe, 就像我们经常在 Linux 上做的)。能这么做的原因在于,这些命令的所有输入输出都可以通过 Node.js 中 streams 的方式呈现给我们使用。
需要注意的是,我在这篇文章中使用的所有例子都是基于 Linux 系统的,如果你是 Windows 用户,你需要把这些命令转换成对应的 Windows 命令。
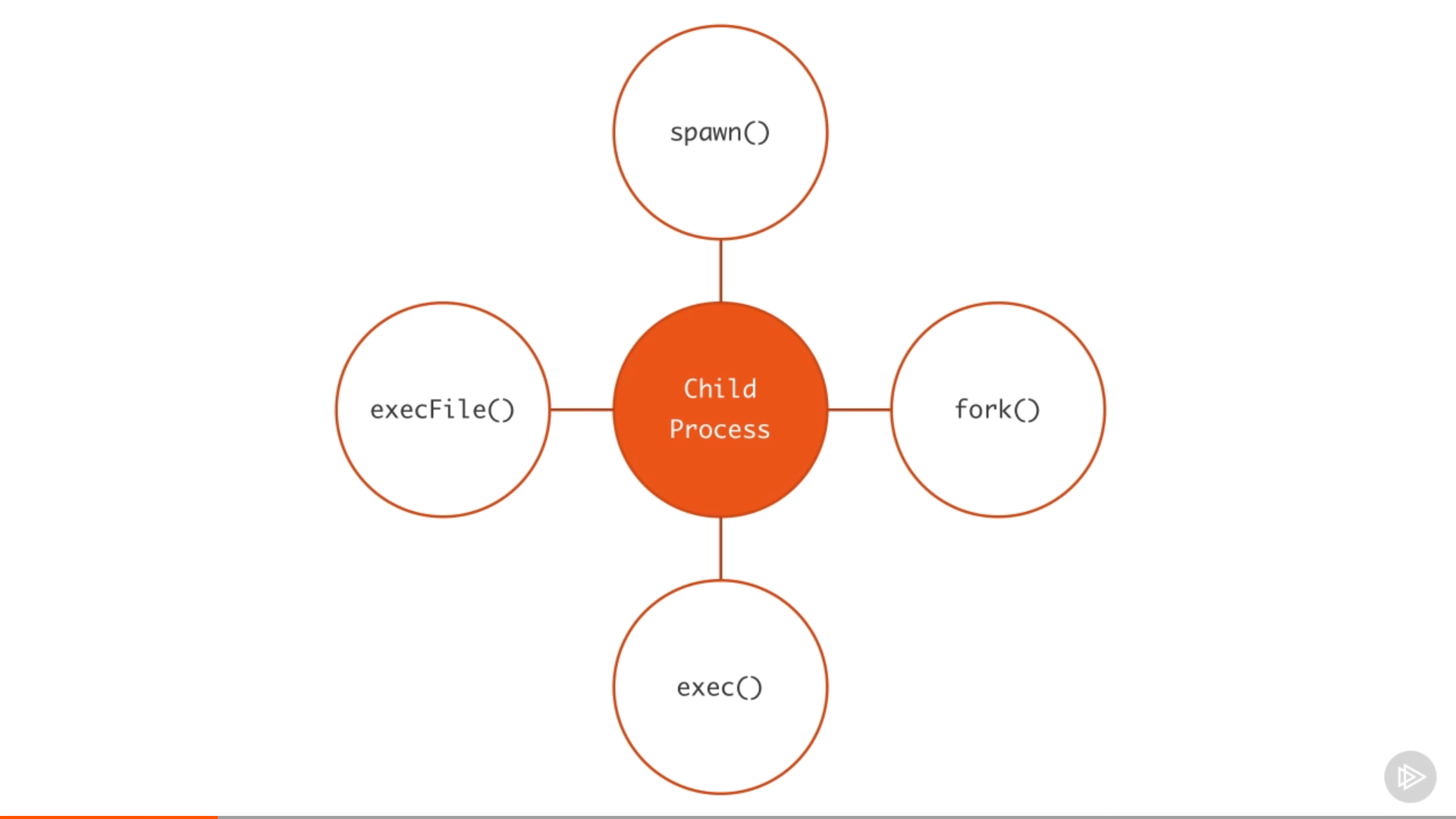
在 Node 中,一共有四种不同的方式创建一个子进程:spaw()、fork()、 exec() 和 execFile()。
好了,下面开始分别介绍这四个函数和它们的区别,以及该在什么时候使用它们。
Spawned Child Processes
spawn函数在一个新进程中运行命令,并且我们可以传递任何参数给该命令。下面的代码创建了一个新进程用于执行pwd命令。
const { spawn } = require('child_process')
const child = spawn('pwd')
如上所示,我们从child_process模块解构获取spawn函数,然后把操作系统命令pwd作为参数传递给它调用执行。
spawn函数调用返回的对象(上面的child对象)是一个ChildProcess实例,并实现了EventEmitter API。这意味着,我们可以直接在这个 child 对象上注册事件处理函数。比如,我们可以通过注册事件处理函数在子进程退出的时候做一些事情:
child.on('exit', function (code, signal) {
console.log(
'child process exited with ' + `code ${code} and signal ${signal}`
)
})
上面的事件处理函数接收了两个参数,code以及signal。signal表示用来终止进程的信号,如果进程是正常退出的,它的值是 null。
除了exit,其他我们可以在ChildProcess实例上监听的事件还有disconnect、 error、close,以及message。
disconnect事件是当父进程手动调用child.disconnect函数时触发的。error事件是当进程不能被spawned或被killed的时候触发的。close事件是当一个子进程的stdio流被关闭的时候触发的。message事件是最重要的一个事件。它是当子进程调用process.send()函数发送消息的时候触发的。这是父/子进程进行通信的方式。下面我们来举例说明这个过程。
每一个子进程都能获取到三个标准stdio流,我们可以通过child.stdin,child.stdout以及child.stderr访问它们。
当这些流被关闭的时候,使用它们的子进程会触发close事件。close事件和exit不同,因为多个子进程可以共享同一个stdio流,所以当一个子进程退出的时候并不意味着这个流被关闭了。
因为所有的流也都是event emitter,所以我们可以在子进程的stdio流上监听不同的事件。和通常的进程不同,在子进程中,stdout/stderr流是可读流,而stdin是可写流,这正好和主进程中的对应流类型相反。在这些流上我们能使用的都是一些标准事件。在可读流上能够监听的最重要的事件是data事件,在该事件的处理函数中我们可以获得命令执行后的输出或者执行命令时候的错误。
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`)
})
child.stderr.on('data', (data) => {
console.error(`child stderr:\n${data}`)
})
上面代码中的两个事件处理函数会打印相关内容到主进程的stdout和stderr。当我们执行上面的spawn函数的时候, pwd命令的输出会被打印,然后子进程正常退出(exit code等于0,意味没有错误发生)。
我们可以把被执行的命令需要的参数组装成一个数组,作为spawn函数调用的第二个参数。举个简单的例子,在当前目录执行find命令并且带上参数-type f(只列出文件),我们可以这样做:
const child = spawn('find', ['.', '-type', 'f'])
如果在执行命令的时候发生错误,比如,上面的例子我们给find命令一个无效的目录,child.stderr的data事件会被触发,并且exit事件处理函数接收到的 exit code 等于 1,表示有一个错误发生了。具体的错误值依赖于宿主操作系统和错误类型。
子进程的stdin是可写流。我们可以利用这点给被执行的命令输入内容。和其他可写流一样,最简单的消费这个流的方式是使用pipe函数。我们可以简单地把一个可读流导向一个可写流。因为主进程的stdin是一个可读流,我们可以把它导向一个子进程的stdin流。如下所示:
const { spawn } = require('child_process')
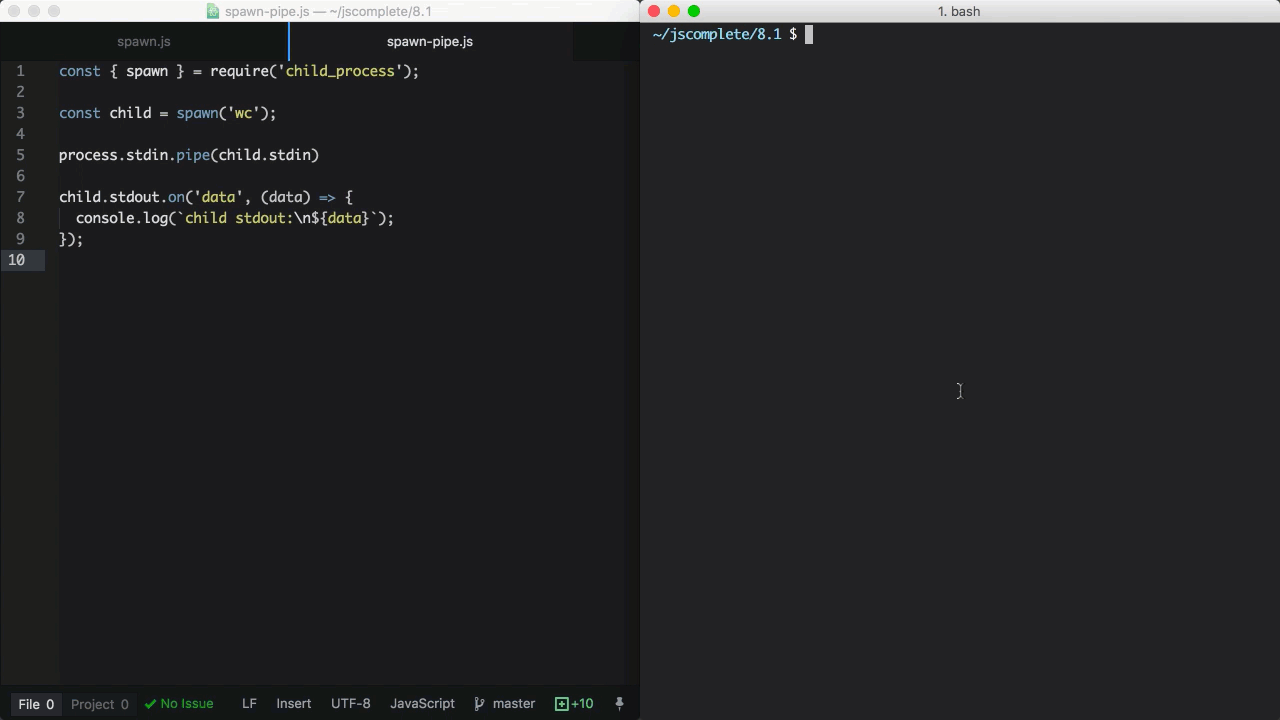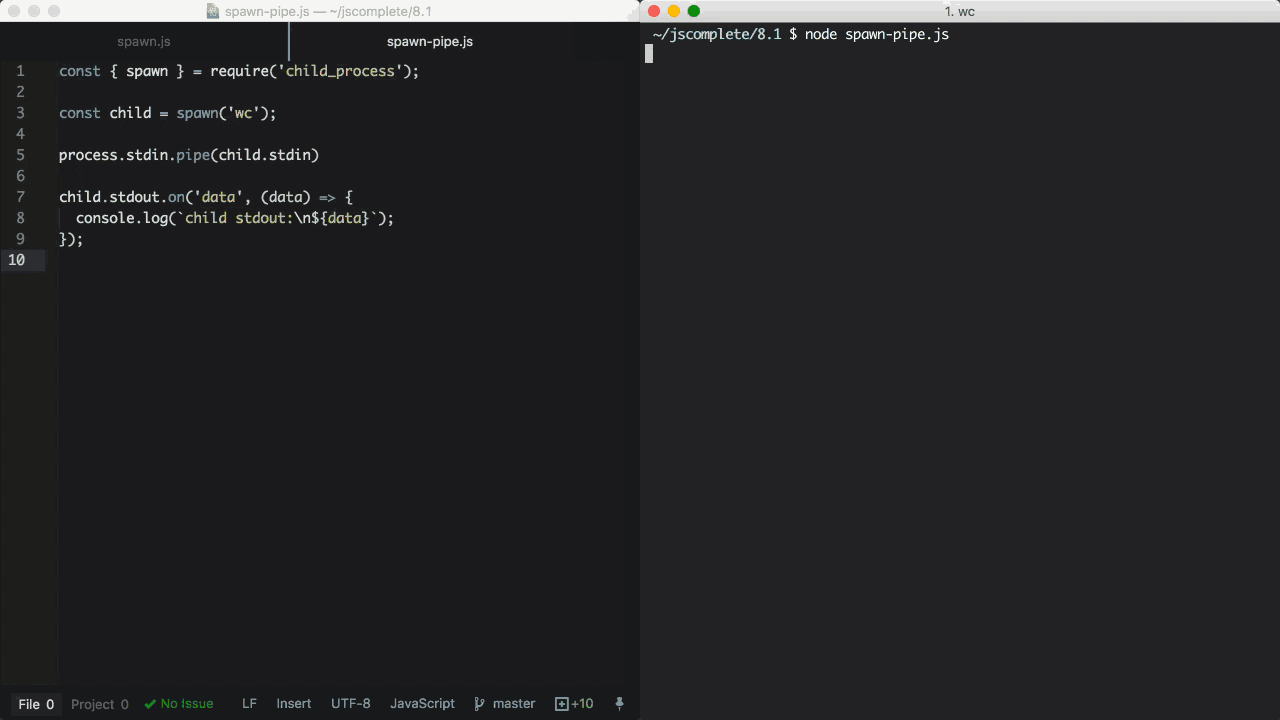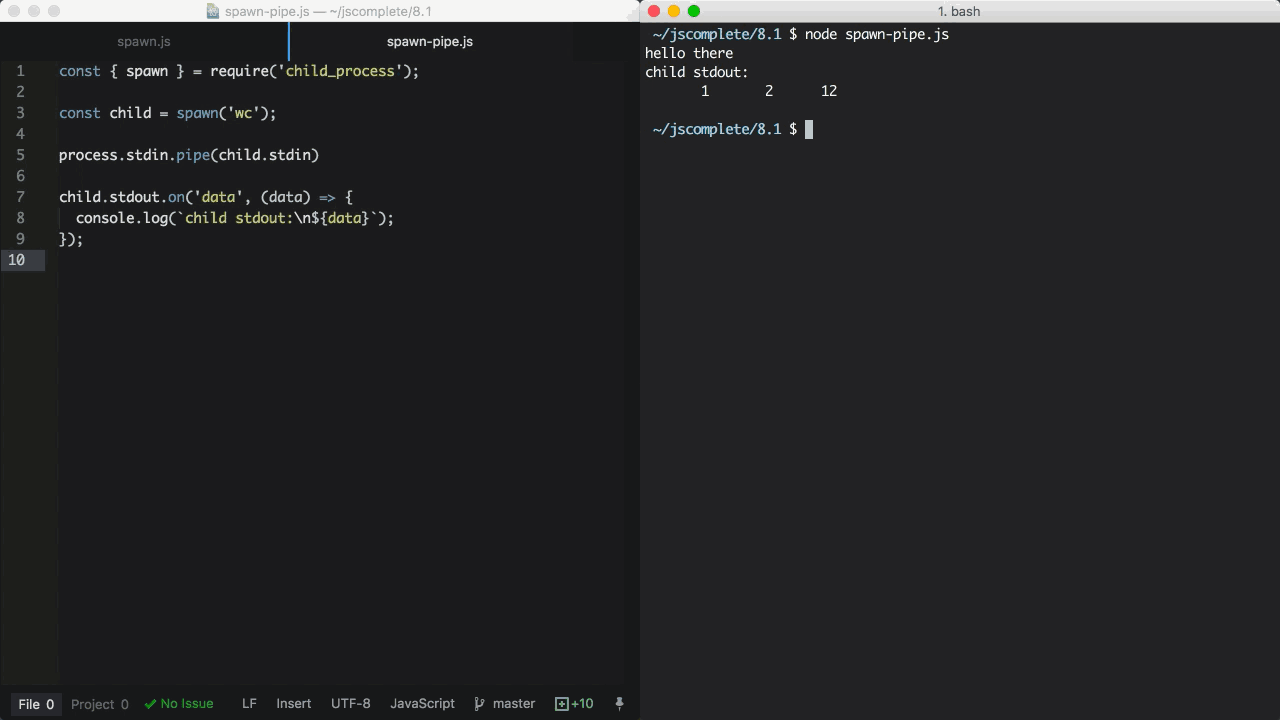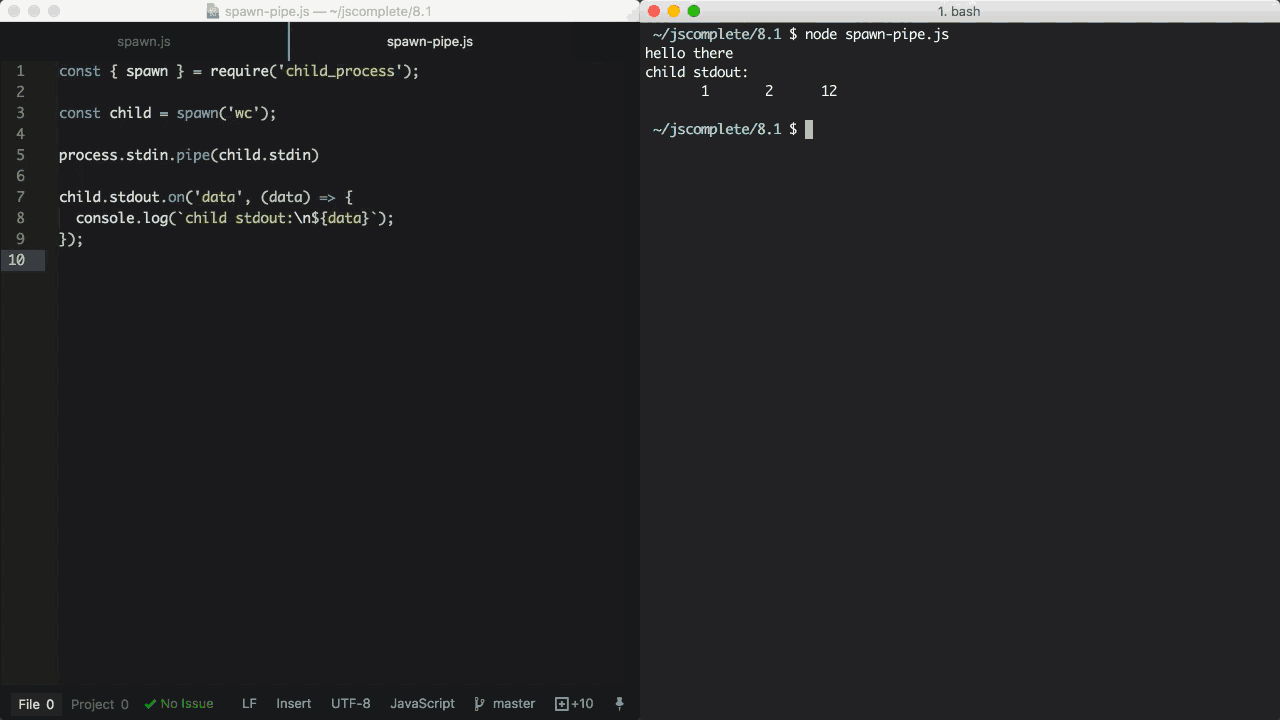
const child = spawn('wc')
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`)
})
在上面的例子中,子进程执行了wc命令,这个命令在 Linux 系统中用于统计行数、单词数、以及字符数。然后我们把主进程的stdin(可读流)导向子进程的stdin(可写流)。这样做的结果是,我们可以在标准输入键入一些内容,然后按Ctrl+D,键入的内容会被作为wc命令的输入使用。
多个进程的标准输入输出可以相互之间导流,就像我们在使用 Linux 命令时做的一样。比如,我们可以把find命令的stdout导向wc命令的stdin去计算当前目录下所有文件的数量:
const { spawn } = require('child_process')
const find = spawn('find', ['.', '-type', 'f'])
const wc = spawn('wc', ['-l'])
find.stdout.pipe(wc.stdin)
wc.stdout.on('data', (data) => {
console.log(`Number of files ${data}`)
})
我给wc命令加了-l参数,使它只统计行数。上面的代码执行后,会输出当前目录下所有文件的数量。
shell 语法和 exec 函数
默认情况下,spawn函数不会创建一个 shell 去执行我们传递的命令。这使得它的性能略微强于exec函数,后者会创建一个 shell 去执行命令。exec函数还有一个不同的地方在于,它会缓冲命令产生的输出,并且一次性把整个输出传递给回调函数,而不是像spawn那样使用流的方式。
下面是之前find | wc的例子改用exec函数实现后的代码。
const { exec } = require('child_process')
exec('find . -type f | wc -l', (err, stdout, stderr) => {
if (err) {
console.error(`exec error: ${err}`)
return
}
console.log(`Number of files ${stdout}`)
})
因为exec函数会使用 shell 去执行命令,所以我们可以直接使用 shell 的pipe语法。
需要特别注意到的是,使用 shell 语法在执行一些外部提供的动态输入时会存在安全风险。一个用户可以很容易地使用 shell 语法字符比如;和$来实现命令注入攻击(比如,command + '; rm -rf ~)。
exec缓冲所有输出并传递给exec回调函数的stdout参数。这个stdout就是我们想要打印的命令的输出。
如果你需要使用 shell 语法并且所执行命令期望的数据量比较小,那exec函数是不错的选择。记住,在执行结束之前,exec会把整个数据缓存在内存中。
相反的,如果所执行命令期望的数据量很大,spawn函数是更好的选择,因为它可以使用标准输入输出流的方式消费数据。
如果需要,我们还可以让spawn创建的子进程继承父进程的标准 IO 对象。并且更重要的是,spawn函数也支持 shell 语法。下面的例子展示了这一点:
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true,
})
因为设置了stdio: 'inherit',在执行代码的时候,子进程会继承主进程的stdin,stdout,stderr。这会使子进程data事件处理函数的打印输出到主进程的标准输出中。
又因为设置了shell: true,我们得以像exec函数调用一样使用 shell 语法传递命令。另外,我们依然能够享受spawn函数流数据的优势。这相当于整合了两个函数最好的部分。
除了shell和stdio配置项,我们还可以在spawn的第二个参数中设置更多的选项。比如,我们可以设置cwd来改变当前脚本的工作目录。下面的代码展示了如何统计/Users/samer/Downloads目录下的文件数量。cwd选项使脚本统计~/Downloads目录下的文件数量。
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true,
cwd: '/Users/samer/Downloads',
})
另一个我们可以使用的选项是env,用于指定新的子进程可访问的环境变量。这个选项的默认值是process.env,它使得任何命令可以访问当前进程的环境变量。如果我们想改变这个行为,我们可以简单地传一个空对象给env选项或者一个非空对象,它包含的值就是子进程能够访问的所有环境变量。
const child = spawn('echo $ANSWER', {
stdio: 'inherit',
shell: true,
env: { ANSWER: 42 },
})
因此上面的echo命令不能访问父进程的环境变量,比如,不能访问$HOME。但是,它可以访问$ANSWER,因为这个是我们传递给env选项的自定义环境变量。
最后一个需要在这里解释的重要选项是detached。它可以使得子进程独立于父进程运行。假设我们有一个timer.js文件:
setTimeout(() => {
// keep the event loop busy
}, 20000)
我们可以使用detached选项让它在后台执行:
const { spawn } = require('child_process')
const child = spawn('node', ['timer.js'], {
detached: true,
stdio: 'ignore',
})
child.unref()
detached的子进程的确切行为依赖于具体的操作系统。在 Windows 和 Linux 上的行为并不完全一致。
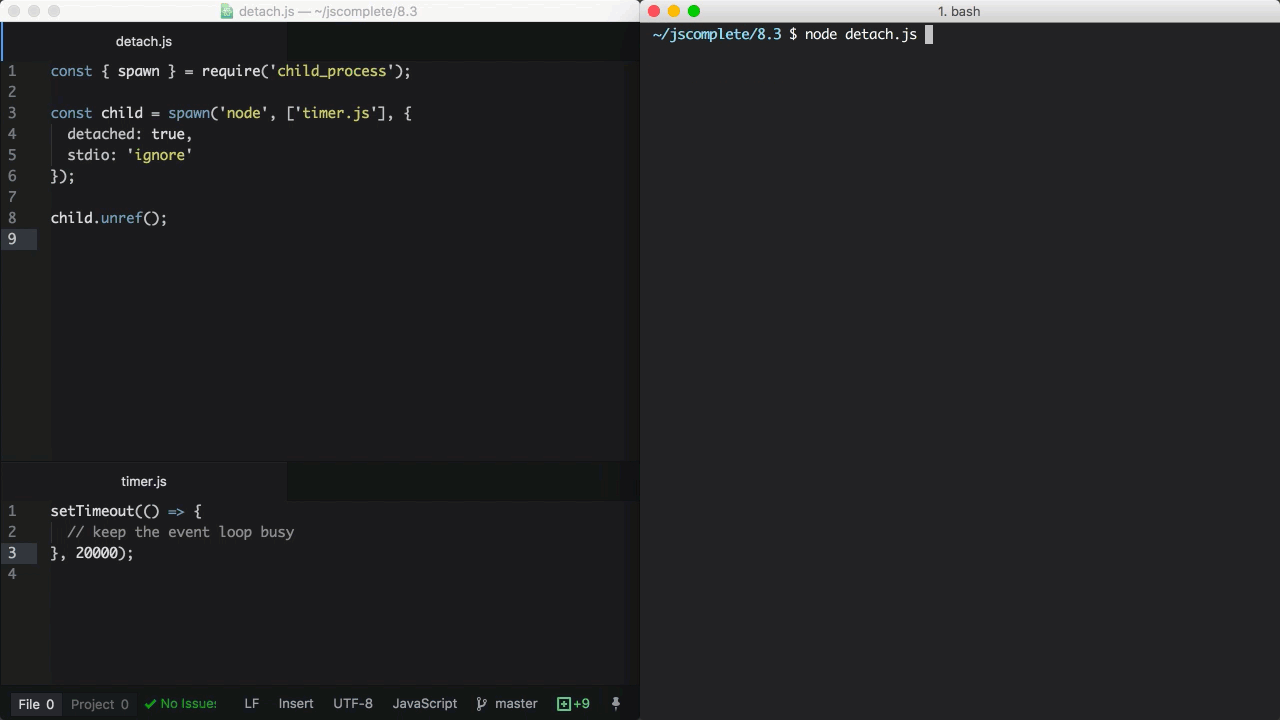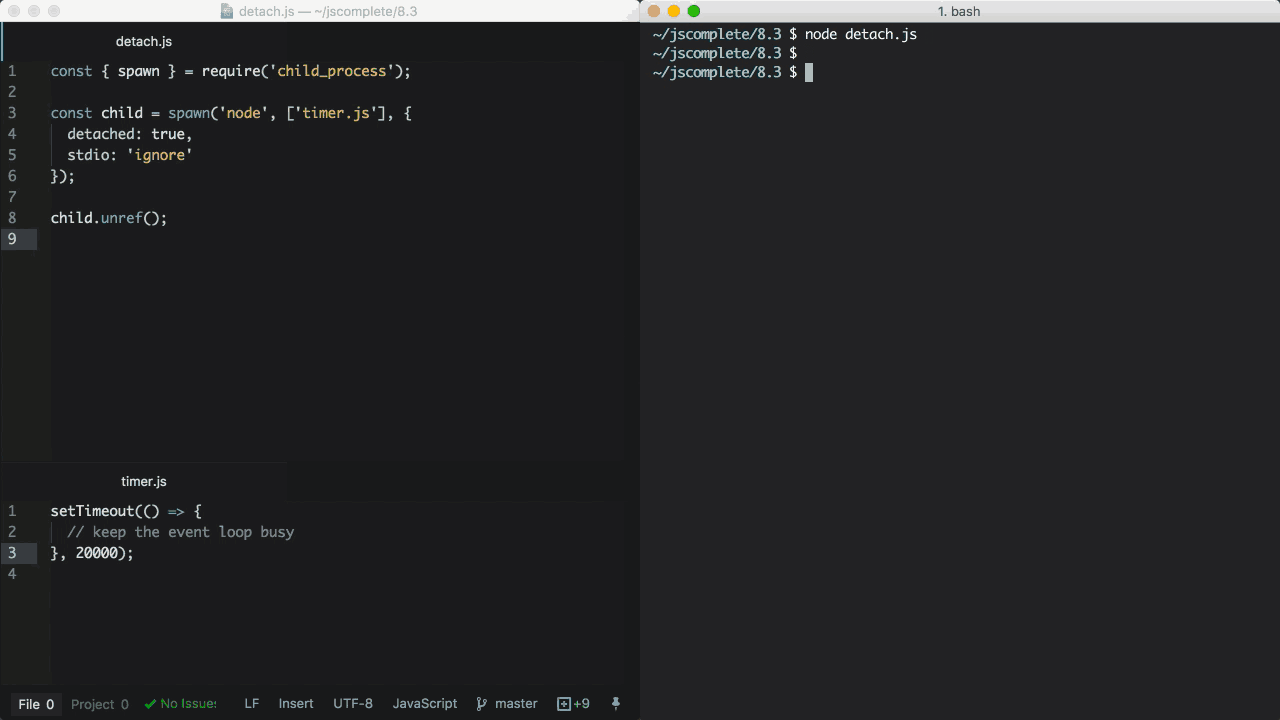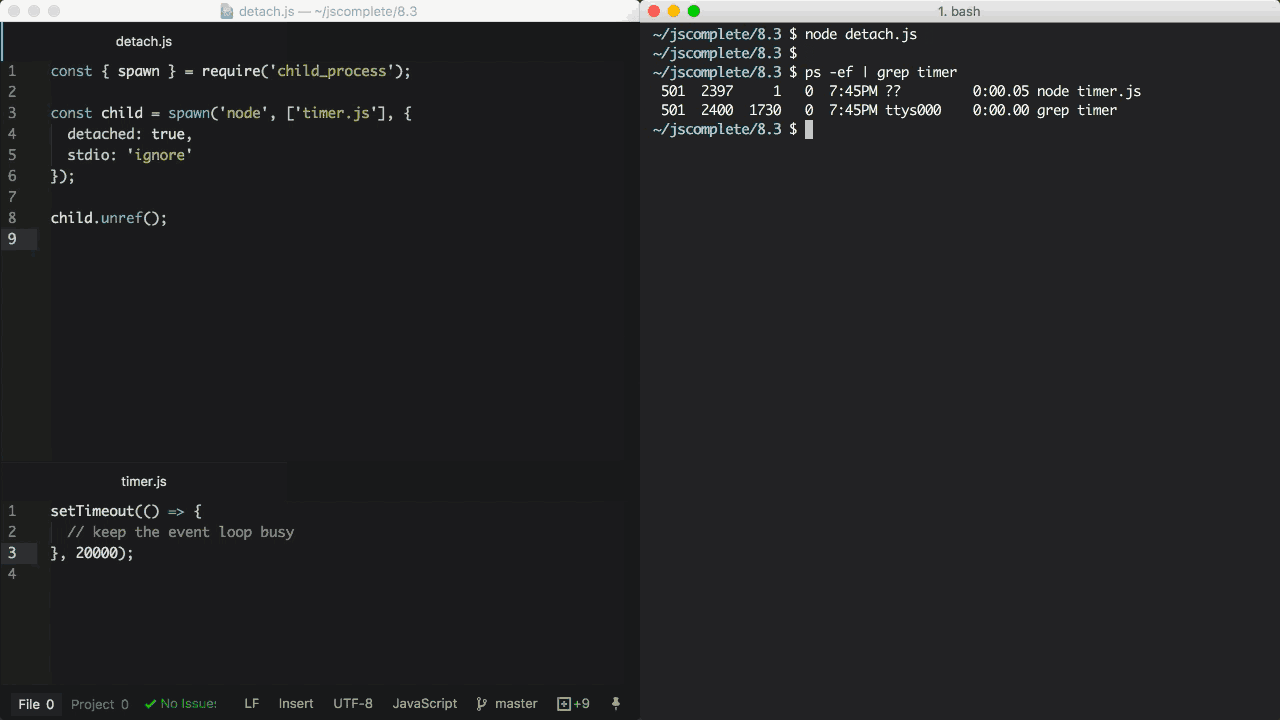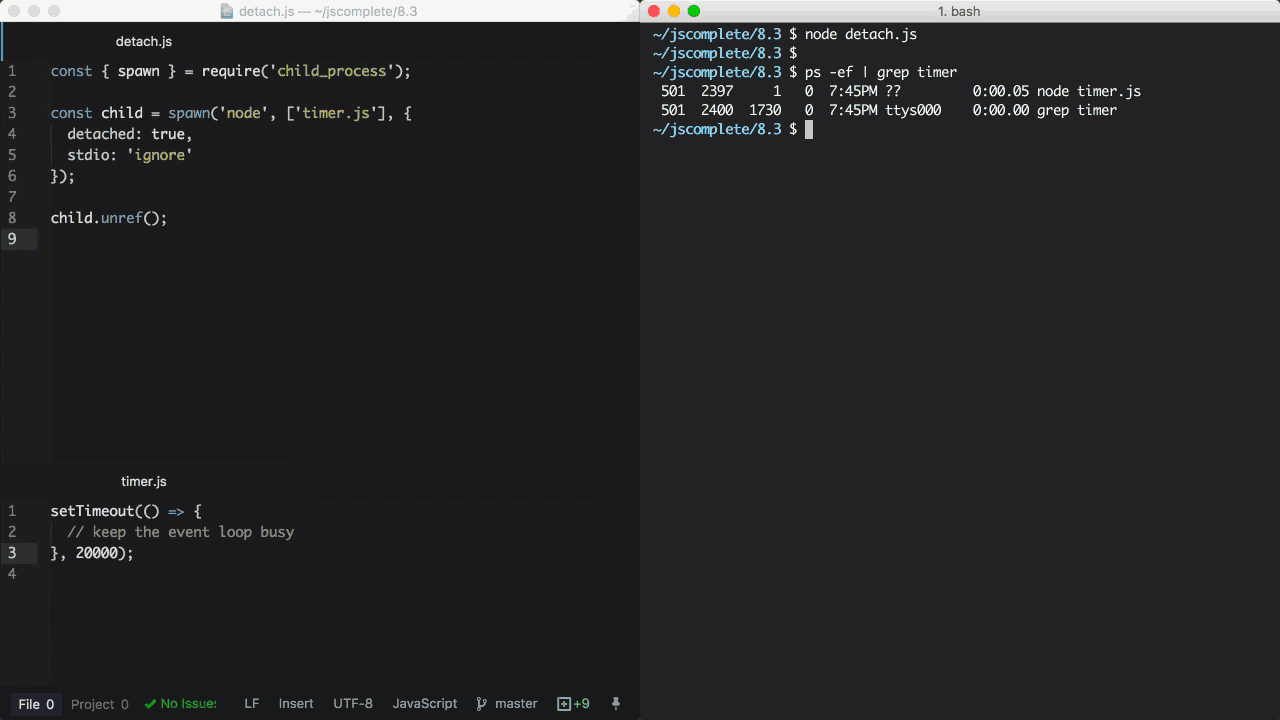
如果在独立运行的子进程上调用unref方法,那么父进程可以退出并且不会影响子进程的运行。这对于那些会执行很长时间的子进程非常有用。保持在后台运行的另一个条件是子进程的stdio也要配置成独立于父进程。
上面的例子通过detached和stdio的设置独立运行timer.js脚本,即便父进程终止退出子进程依然能够在后台运行。
execFile 函数
如果你需要执行一个文件,并且不使用 shell,execFile 正是你所需要的。它的表现和 exec 函数一样,不过不使用 shell 使它的效率会稍高一些。在 Windows 上,有些文件不能独立执行,比如.bat或者.cmd文件。这些文件不能通过execFile执行,但可以通过exec或者 shell 选项设置为 true 的spawn函数执行。
*Sync 函数
child_process模块的spawn,exec和execFile函数,都有对应的同步阻塞执行的版本。
const { spawnSync, execSync, execFileSync } = require('child_process')
这些同步函数在某些简化脚本任务或启动处理任务的场景中很有用处,其他情况下最好避免使用。
fork 函数
fork函数是spawn函数的一种变体,用于创建 node 进程。两者之间最大的区别是,在调用fork函数的时候,父子进程之间创建了通信的渠道。因此我们可以通过forked子进程的send方法以及process对象在父子进程之间交换信息。这个是通过EventEmitter模块接口实现的。举个例子:
parent 文件,parent.js:
const { fork } = require('child_process')
const forked = fork('child.js')
forked.on('message', (msg) => {
console.log('Message from child', msg)
})
forked.send({ hello: 'world' })
child 文件,child.js:
process.on('message', (msg) => {
console.log('Message from parent:', msg)
})
let counter = 0
setInterval(() => {
process.send({ counter: counter++ })
}, 1000)
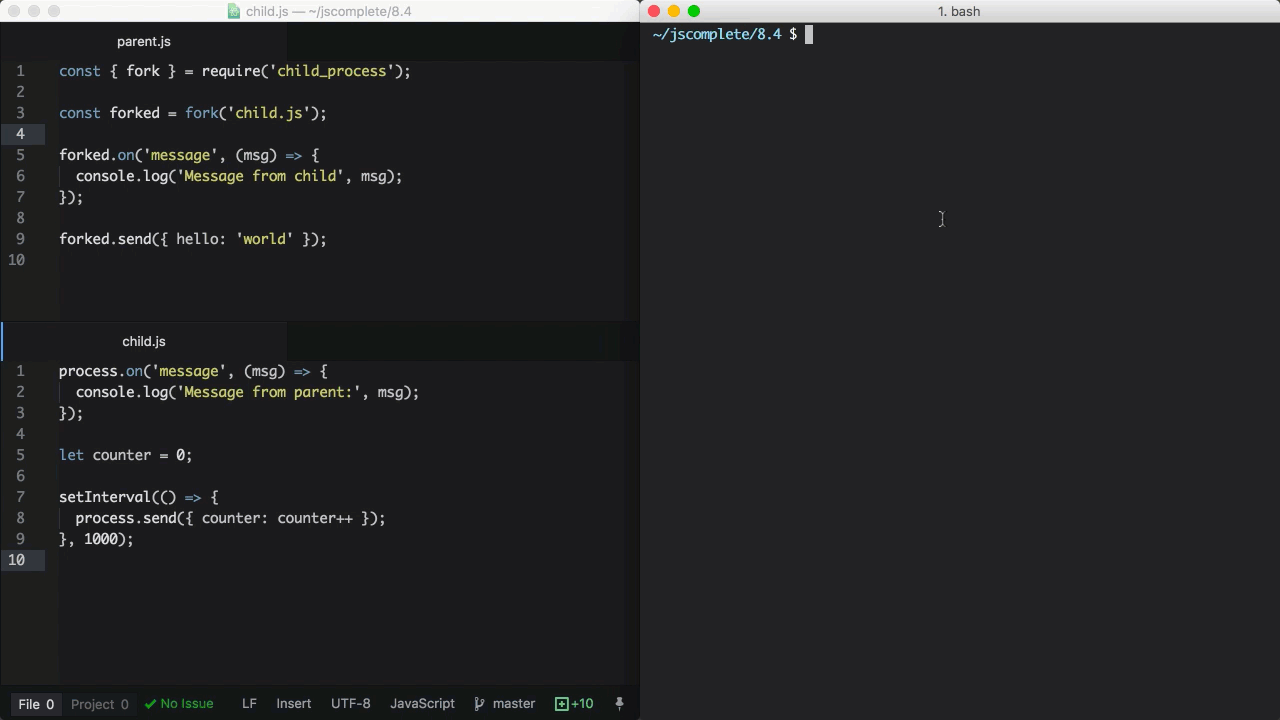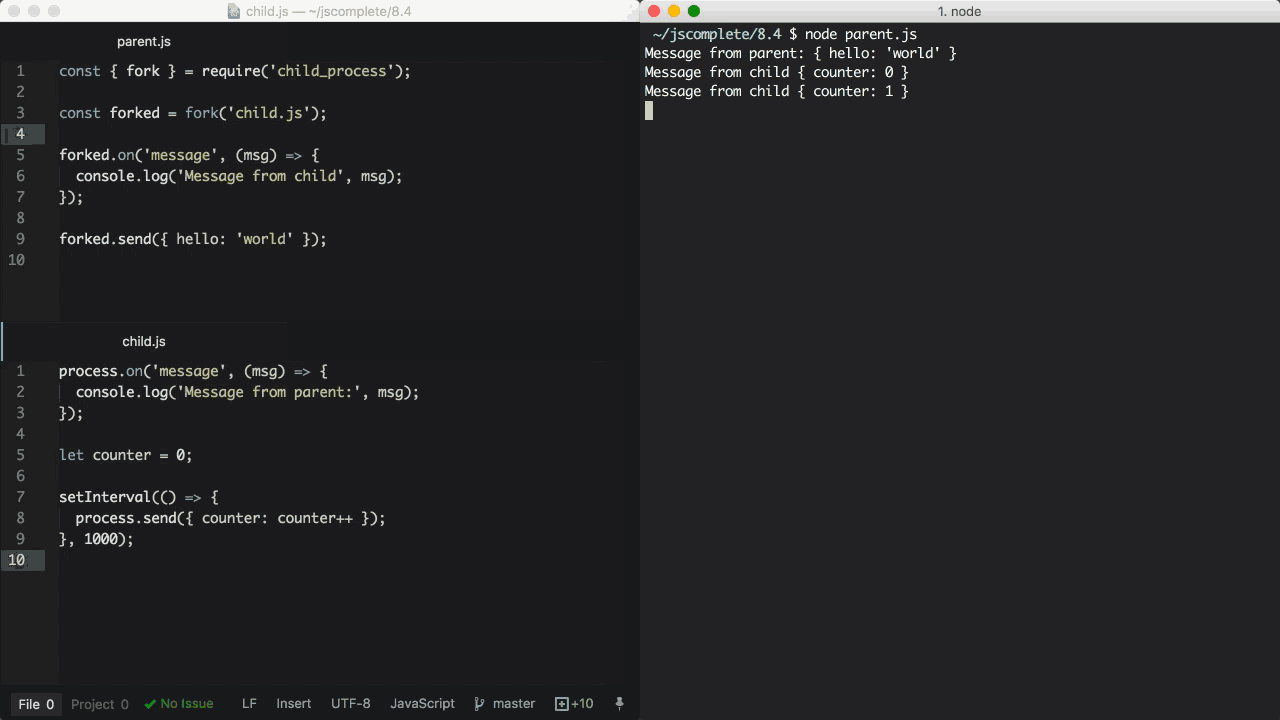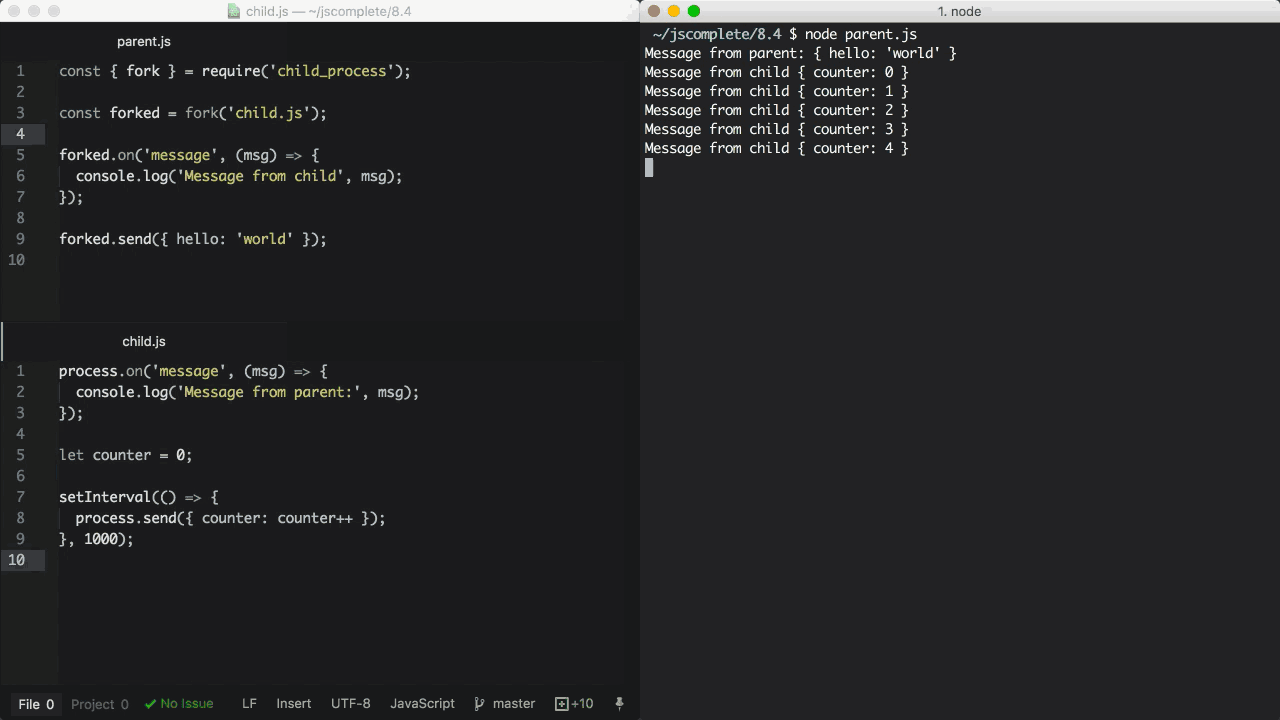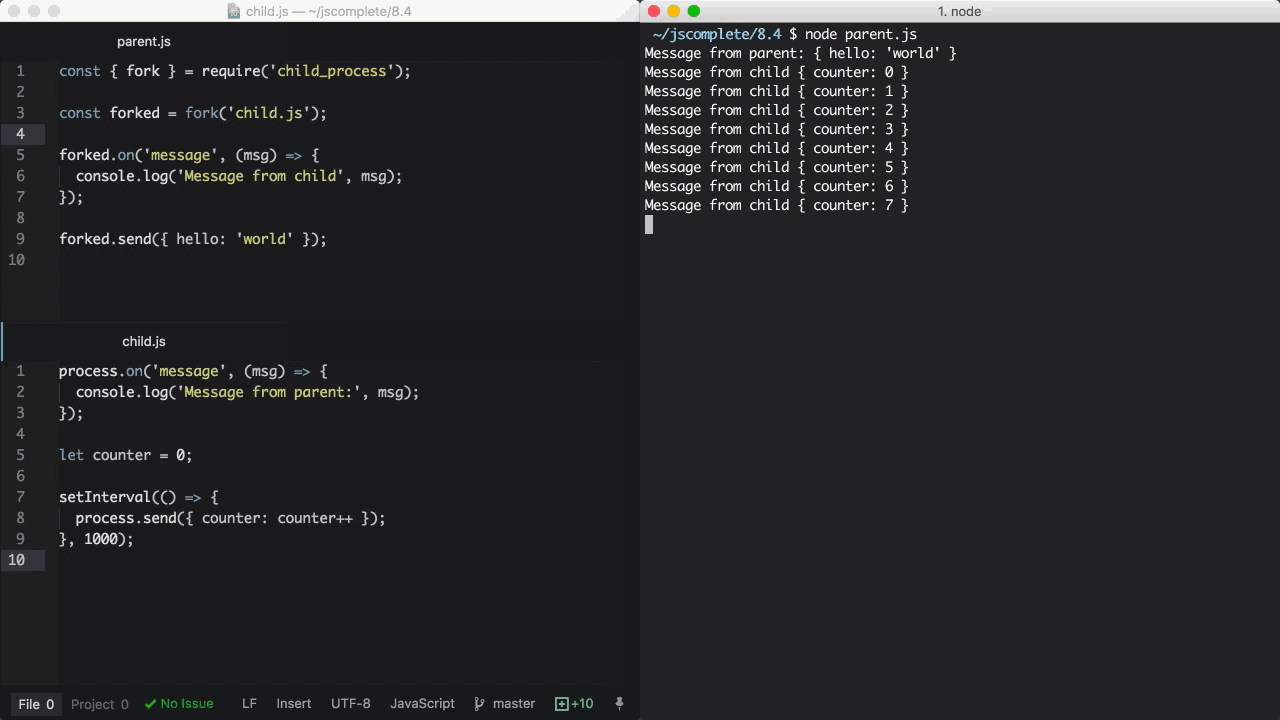
在上面的parent.js中,我们 fork 了child.js(该文件会被node命令执行)并且监听了message事件。这个message事件在每一次子进程调用process.send方法时都会被触发,在这里我们每隔一秒就调用了一次。
为了把消息从父进程传递给子进程,我们可以在 forked 子进程对象上调用send方法,然后在child.js脚本中监听process对象上的message事件。
当我们执行parent.js文件的时候,它首先传递{ hello: 'world'}对象给子进程并且被打印出来。然后,子进程每隔一秒会向父进程发送递增的计数器并且也被打印出来。
我们继续写一个关于fork函数的更实际有用的例子。
假设我们有一个 http 服务器处理两个接口。其中一个接口/compute需要庞大的计算量,因此需要几秒钟才能完成计算。我们可以使用一个长循环来模拟:
const http = require('http')
const longComputation = () => {
let sum = 0
for (let i = 0; i < 1e9; i++) {
sum += i
}
return sum
}
const server = http.createServer()
server.on('request', (req, res) => {
if (req.url === '/compute') {
const sum = longComputation()
return res.end(`Sum is ${sum}`)
} else {
res.end('Ok')
}
})
server.listen(3000)
这个程序有一个非常大的问题,当请求/compute的时候,因为长循环操作占用着执行栈,服务器因此无法继续处理其他请求。
根据不同的耗时操作的类型我们可以有不同的解决方案。但有一个方案对于任何耗时操作都有用,那就是我们可以fork出一个子进程来处理庞大的计算量。
我们首先把longComputatoin函数移到一个独立的文件中,并且根据来自主进程的消息决定何时调用该函数。
以下是这个新的compute.js文件:
const longComputation = () => {
let sum = 0
for (let i = 0; i < 1e9; i++) {
sum += i
}
return sum
}
process.on('message', (msg) => {
const sum = longComputation()
process.send(sum)
})
现在,相比于直接在主进程中运行这个耗时操作,我们可以fork这个compute.js文件,并且使用消息接口在父子进程之间进行通信。
const http = require('http')
const { fork } = require('child_process')
const server = http.createServer()
server.on('request', (req, res) => {
if (req.url === '/compute') {
const compute = fork('compute.js')
compute.send('start')
compute.on('message', (sum) => {
res.end(`Sum is ${sum}`)
})
} else {
res.end('Ok')
}
})
server.listen(3000)
经过修改后,当请求/compute接口时,我们只是发送了一个消息给子进程通知它开始执行耗时的操作,因此父进程的事件循环不会被阻塞。
当子进程执行完这个耗时操作后,它会通过process.send方法把计算结果返回给父进程。
在父进程中,我们在 fork 出的子进程对象上监听message事件,当该事件触发的时候,我们就能拿到计算结果sum,然后返回给请求用户。
以上就是本文的所有内容。